 腾讯登录
腾讯登录【Advanced Science】西班牙研究学者发文:糖尿病临床研究有前景的途径
| 导读 | 研究人员建立了一个全面的评估框架,以评估这些数据在机器学习任务中的效用,并将分析范围扩展到标准指标之外,以阐明模拟疾病轨迹的生物医学合理性。 |
近日,西班牙安达卢西亚进步与健康公共基金会等单位合作共同在期刊《Advanced Science》上发表了研究论文,题为“High-Fidelity Synthetic Data Replicates Clinical Prediction Performance in a Million-Patient Diabetes Cohort”,本研究中,研究人员利用双对抗自编码器合成了源自安达卢西亚人口健康数据库中近 100 万糖尿病患者的真实世界纵向数据集。研究人员建立了一个全面的评估框架,以评估这些数据在机器学习任务中的效用,并将分析范围扩展到标准指标之外,以阐明模拟疾病轨迹的生物医学合理性。
医疗保健数字化:数据激增、去识别挑战与重新识别风险评估
01
医院和医疗保健机构的数字化催生了一个时代,在这个时代,医疗保健系统已成为数据生成量最大的领域之一。这种数字化转型导致了各种各样的大量数据集呈指数级增长,涵盖了众多患者信息、临床记录和与健康相关的变量。据目前估计,超过 30% 的现有数据是在医疗保健环境中生成的。这些丰富的数据来源为新生物医学知识的创造奠定了基础,使研究人员能够从真实世界的患者经历和结果中获得见解,为不断扩大的真实世界证据(RWE)领域做出了贡献。在推动电子健康记录(EHR)的二次利用的同时保护敏感医疗数据,医疗保健机构采用了去识别技术来创建匿名数据集。然而,去识别虽然降低了隐私风险,但并不能完全保证免受重新识别尝试或将患者数据与外部来源关联的攻击。为评估并降低重新识别的风险,人们已对多种方法进行了研究,尤其侧重于个体患者的轨迹模式。实际上,当对患者轨迹进行充分观察时,其会保留独特的特征,从而加大重新识别的风险。
静态预测性能
02
当按糖尿病诊断年份对模型的预测性能进行细分时,AUROC 分数随时间推移持续提升的趋势十分明显。无论是基于真实数据还是合成数据训练的模型,都呈现出这一趋势。如图所示,基于合成数据副本训练的模型始终紧跟基于原始数据训练的模型的性能,尽管存在细微但持续的性能差距。此外,基于真实数据和合成数据增强数据集训练的混合模型的性能几乎与仅基于真实数据训练的模型重合,表明在这种情况下数据增强并未提供额外的预测价值。在基于原始数据训练的模型中,男性模型的表现比女性模型更稳定,这一模式在基于合成数据训练的模型中也得到了重现。与整体 AUROC 结果一致的是,当分别对两性进行分析时,用合成样本扩充数据并未带来性能提升。研究人员还报告了每年评估的患者总数,以及按性别划分的患者数,同时还报告了 AUROC 得分的均值和标准差。
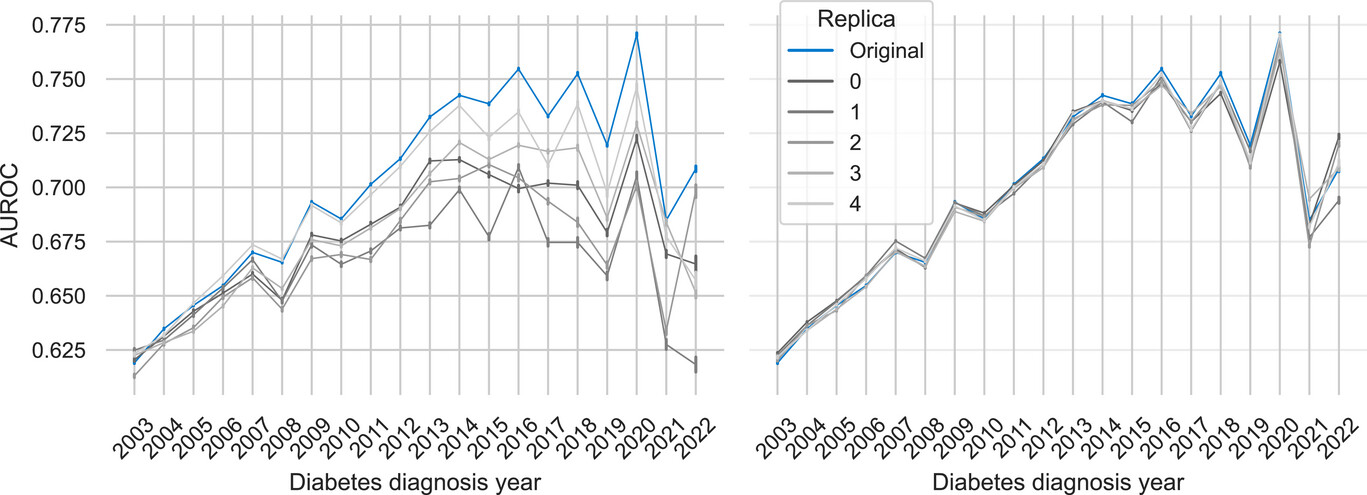
按糖尿病诊断年份划分的预测性能(AUROC)(SSMR-优化版)
结论
03
综上,研究人员证明,从一个包含超过 100 万糖尿病患者的大型真实世界队列中生成的高保真合成数据,能够在一项具有临床相关性的任务中成功复制真实数据的预测性能。
参考资料:
https://advanced.onlinelibrary.wiley.com/doi/10.1002/advs.202516196(转化医学网360zhyx.com)
【关于投稿】
转化医学网(360zhyx.com)是转化医学核心门户,旨在推动基础研究、临床诊疗和产业的发展,核心内容涵盖组学、检验、免疫、肿瘤、心血管、糖尿病等。如您有最新的研究内容发表,欢迎联系我们进行免费报道(公众号菜单栏-在线客服联系),我们的理念:内容创造价值,转化铸就未来!
转化医学网(360zhyx.com)发布的文章旨在介绍前沿医学研究进展,不能作为治疗方案使用;如需获得健康指导,请至正规医院就诊。
责任声明:本稿件如有错误之处,敬请联系转化医学网客服进行修改事宜!
微信号:zhuanhuayixue










还没有人评论,赶快抢个沙发